NFL Predictions
Shelter Animal Outcomes
Summary
Every year, approximately 7.6 million companion animals end up in US shelters. Using three different classifiers the final outcome of an animal is predicted. They could be adopted, transfer to other shelters or foster homes, return to their owners or in worst case scenario died or being euthanised. Using data from Austin Shelter collected in a period of 3 years for cats and dogs, the paper present implementation in python for data analysis. The models are train and then predictions of the outcomes are made. All three models yield similar results, but it is decision trees that with an accuracy of 62% turns out to be the best classifier. It provides a easy set of rules to be implemented as an animal arrives to the shelter.The three most important features are Neutered Male, Spayed Female and Age.
Introduction
“Every year, approximately 7.6 million companion animals end up in US shelters. Many animals are given up as unwanted by their owners, while others are picked up after getting lost or taken out of cruelty situations. Many of these animals find forever families to take them home, but just as many are not so lucky. 2.7 million dogs and cats are euthanized in the US every year.”1 During all my life I have had the opportunity to have furry companions, but I have never really do something for others than my pets. Using data from Kaggel I would try to predict the outcome for each animal in the dataset. There are five possible outcomes: adoption, return to owner, transfer, died and euthanasia. In an ideal world all animals should find a family that take care of them, and shelter help in doing so. But there are some animals that are more difficult to allocate. What does this animals have in common, how to identify them so that shelters can focus on helping them find a place to live with a caring family.
From the analysis point of view this is a classification issue, given certain features a prediction would be made. The final model would provide information about which animals are the more likely to get a home. It would also tell those animals that may need an extra help to get to a safe place.
Data Preprocessing
This task is performed using data from Austin Animal Center. The largest no-kill animal shelter in United States. The dataset has records of cats and dogs that stayed at the shelter at some point between October 2013 and February 2016. Two datasets are given one for training and one for testing. However, the testing data does not have the data about the outcome of the animals making impossible to measure model accuracy. The training dataset is large enough to create both training and testing sets as it has over 26 thousand instances.
The dataset has a total of 26,729 cases with data that describes each animal. It has the animal id, name if known, date, outcome (adoption, transfer, etc), type (cat or dog), sex, time that stayed at the shelter, breed, color. All of them are presented as categorical attributes. The levels of all useful attributes is the following: AnimalType is a 2 level; outcomesubtype has 16 levels, but is not possible to use in the classification as is part of the target attribute; Sex is a 5 level variable; age is a 44 level variable that has been processed to have a numerical value for descriptive analytics, there are 1,380 breeds and color has 367 levels.
The data has missing values but mostly in the attribute “outcomesubtype” that would not be part of the training set as it has information about the outcome of each animal. Age has 18 missing values that are being replace with the mean age. Finally Sex attribute has one missing value, the instance is deleted.
In order to replicate the scenario created by Kaggle a test dataset must be created from the training set. To that end a unique list of animals was created from which 80% was randomly selected to be part of the training set, and the remaining 20% of animal would be in the testing set. The target instance for each pet is extracted from the data as well. In total and after deleting some instances due to missing values there are 21,382 animals in the training set and 5,346 animal in the testing set. All data preprocessing was included in the function called GetData(). It takes the name file to be read, original training file from Kaggle and a the value to define the size of test dataset, as a percentage of the data. The function has the following default parameters: G etData( fileN =’ train.csv’, test_size =0 .2) . The function returns the folds for training and testing as four panda data frames divided between the training and target attributes.
The function would load the data into a data frame, immediately after it would transform the age into a numerical attribute storage as days. In addition would replace the missing values for this attribute with the mean and remove the missing values previously described. Once the data is clean all variables to be use are copied to a new data frame (AnimalID, OutcomeType, AnimalType, SexuponOutcome, AgeuponOutcome, Breed and Color). For each one of this attributes dummy variables are created resulting with over 1,500 features to be use. Using train_test_split from scikitlearn module the training and testing animal ids are selected randomly. The final step is to get the data for each set.
Exploratory Data Analysis
The data show that the most common outcome is adoption or transfer to either other shelters or possible foster families. Unfortunately despite the efforts of the shelter not to kill animals, euthanasia is not the least possible outcome. There are many animal that eventually get back to their families. Adoption is the most frequent outcome followed by transfer. The shelter might not deal with some breeds? is it operating at full in capacity?
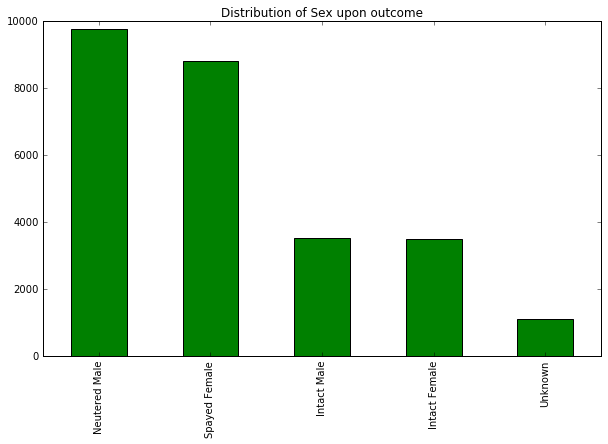

When an animal arrives to the shelter it is more likely to be a dog than a cat. Animals that are neutered or spayed have greater possibilities to be adopted, why? Intact Animals are moved to other shelters, it could be that other shelters want intact animals. Neutered animals are also transferred possibly as part of rotating programs? We do not know if foster families are considered a transfer and it might be the case since is not part of the outcome options.
The average age of a pet when it leaves the shelter is two years and two months. Idealy we would want to see a normal distribution. That would mean that all outcomes happens for any animal regardless of its age. In the graph 3 “Age to Outcome” shown below we see that animals that are 60 days old have a great possibility of being adopted. People are looking for cubs to grow. When the animals are between one and two years there are three good outcomes for the Austin Shelter. They are either adopted, transfer or return to their family. One interesting aspect of the data is that animals that get lost of escape from home and return to their owners are mostly 3 years or older.
The average age of a pet when it leaves the shelter is two years and two months. Idealy we would want to see a normal distribution. That would mean that all outcomes happens for any animal regardless of its age. In the graph 3 “Age to Outcome” shown below we see that animals that are 60 days old have a great possibility of being adopted. People are looking for cubs to grow. When the animals are between one and two years there are three good outcomes for the Austin Shelter. They are either adopted, transfer or return to their family. One interesting aspect of the data is that animals that get lost of escape from home and return to their owners are mostly 3 years or older.
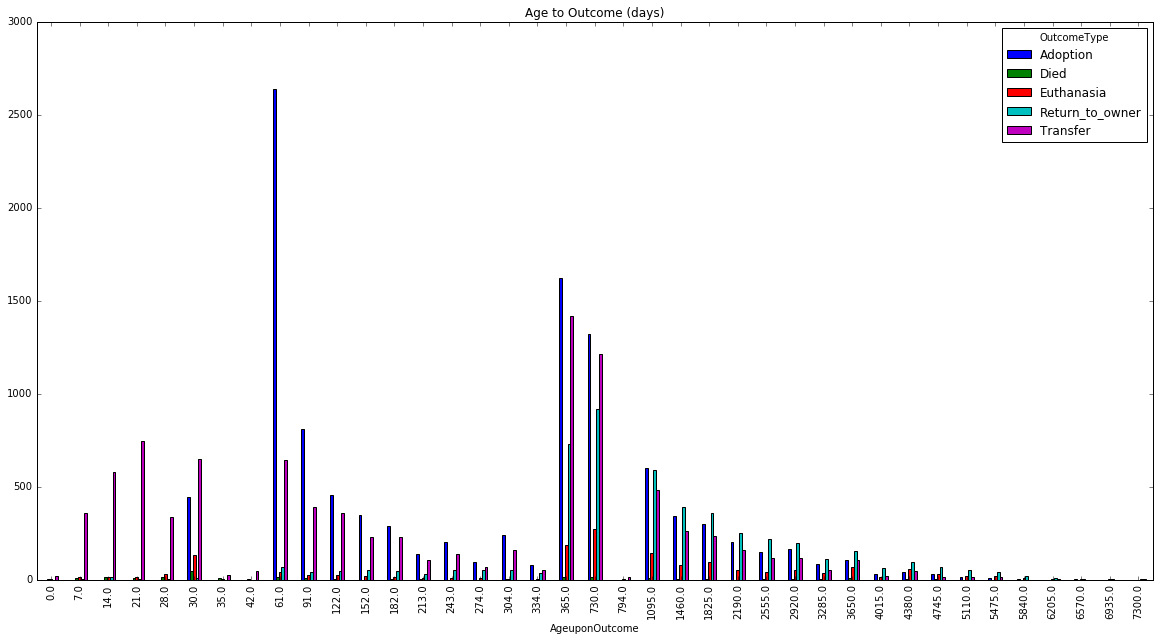
Adoptions and transfers to other shelters happens at any age. These are the two most common outcomes during the first year of life for any type of pet. Pets in bad conditions that are between one or two years old have great probabilities of dying. Adoption, which is the best possible outcome for an animal, has its peak at the second month of life and at 1 year. The trend declines as the animal grows but then it suddenly have another peak at rear 1.
Etuhtanasia’s peak is at two year old, followed by one year old animals. At day 30 of life many animals have the same outcome.
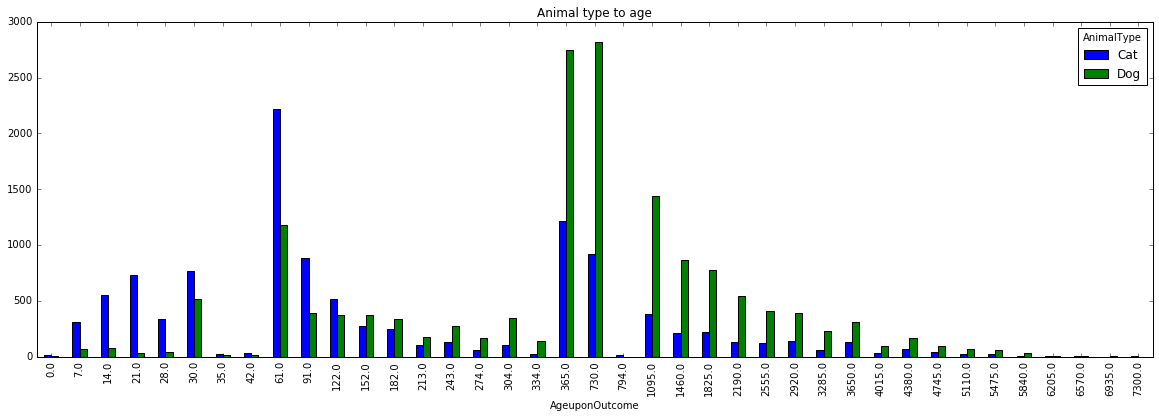
Cats are more likely to be adopted when they are 6 months old. From the outcome to age analysis we learn that adoption’s peak is at day 60. From the graph Animal type to age, we add the information that adoption is more likely for cats, even when they are less in quantity.
From the exploratory analysis we have found out that the animal with more probabilities to be adopted in 2 months is a neutered male cat followed by a spayed female cat. On the other hand an intact male dogs are more likely to be euthanised, followed by intac female dogs.At day 30 many animals are euthanized, and the greates probability is that is a intact male cat.
Cats are more likely to be adopted when they are 6 months old. From the outcome to age analysis we learn that adoption’s peak is at day 60. From the graph Animal type to age, we add the information that adoption is more likely for cats, even when they are less in quantity.
From the exploratory analysis we have found out that the animal with more probabilities to be adopted in 2 months is a neutered male cat followed by a spayed female cat. On the other hand an intact male dogs are more likely to be euthanised, followed by intac female dogs.At day 30 many animals are euthanized, and the greates probability is that is a intact male cat.
Decision Trees
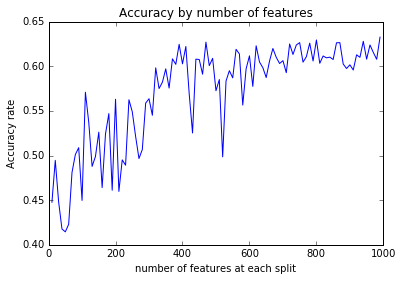
The first model applied to the data is decision trees. Using scikitlearn python package the parameters were tested under a the same random state for comparability. The criterion used was only gini index. The initial tuning was performed to the minimum number of samples required to split an internal node, there was no significant fluctuation in accuracy, for this reason it was fixed at 100. The next parameter tested was max_leaf_nodes, it show that at values between 7 and 13 accuracy was unstable, and it convey at a value of 14 which was the final value. The The maximum depth of the tree was also tested, but the higher accuracy was identify when fixing max_leaf_nodes, and this function ignores the maximum depth when max_leaf_nodes is used. The final attribute was the number of features to consider when looking for the best split. In the graph we see the accuracy against the number of variables used. It start doing worst than a random model, but then it gets better until it conveys around 62% accuracy.
Linear Discriminant Analysis
Implementing Linear Discriminant Analysis LDA gets similar results that decision trees. The overall accuracy is 60% with a confidence interval of ± 4.0%. For both both Decision Trees and LDA cross validation using form scikitlearn was implemented using 10 folds. The model was train and cross validation was implemented over the testing dataset.
For purpose of demonstration Naive Bayes was implemented. But since one essential assumption is that the data must be independent I was expecting nothing from this results. This When applied to the data the overall accuracy is 14%.
Random Forest
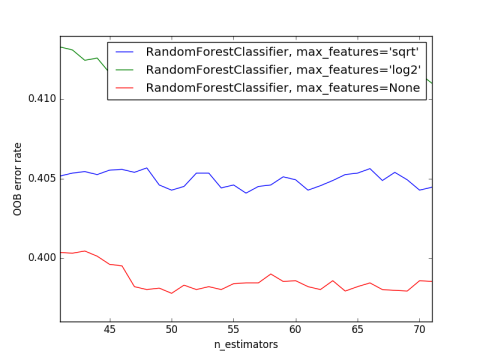
One ensemble method was implemented using Random Forest. Three different approaches were implemented for selecting the number of features us at each decision node. For comparison the Out of Bag Error was computed and is presented in the graph below. This method prove to be as good as decision trees using a reduced number of features at each split. This is good in terms of how many variables are required to see when deciding the outcome of an animal. However the time required to train the model is considerably higher than the time required to run LDA or Decision Trees. For random forest the best model was achieved when using around 50 features. The overall. Using cross validation over the test data set an average accuracy of 40% was identify. However this is considering three different parameters. The best accuracy is at 60% accuracy.
Results and Discussion
The classification problem in this paper was approach using three different classifiers. Decision trees are focus on information gain theory implementing gini index and randomly selecting features to produce the rules at each decision point. The second approach is using linear discrimination allowing to identify thresholds at which the partition of the data provide better results. And the final approach implemented with ensemble methods using decision trees as based learner. The overall results measure with accuracy are similar for all models. It may be best to use decision trees as it is a model that is easy to implement. In addition it provides rules to be applied. It could also be transform into a probabilistic model. Providing information about the possible outcomes for a given animal. This could provide a good support when deciding which animals to follow more closely as they might have a harder time finding a new home. The three most important features are Neutered Male, Spayed Female and Age.
Related posts





